

AI systems don’t just answer questions, they plan, browse, and take actions on your behalf. That leap from chat to autonomy, popularized by the OpenClaw project, is largely powered by “skills” – small tools or add‑ons that instruct an agent how to perform a task, including which services to use and what actions to take.
However, with great power comes great responsibility. As capabilities grow, so does the attack surface – especially when users install new skills into highly privileged AI agents without any security review.
We’ve already observed agentic skills abused to exfiltrate data, download and execute malware, override instructions through prompt injection, and gradually “nudge” an agent’s behavior over multiple interactions before revealing a hidden objective. Yet it’s not only about users making mistakes. AI agents can also autonomously make decisions and choose to install harmful skills, posing a potential supply-chain risk.
In other words, the same modularity that gives agents “their hands” and makes them useful also makes them an attractive delivery mechanism for threat actors.
What abuse looks like in the wild
These threats are not theoretical. ESET telemetry already shows hundreds of malicious skills designed to abuse the lack of security in this area.
One example is a weather forecast skill that allows the AI agent to query a free service such as Open‑Meteo. However, under the hood, an infostealer gathers user secrets such as session tokens and API keys, and then exfiltrates that valuable data to an attacker‑controlled server.
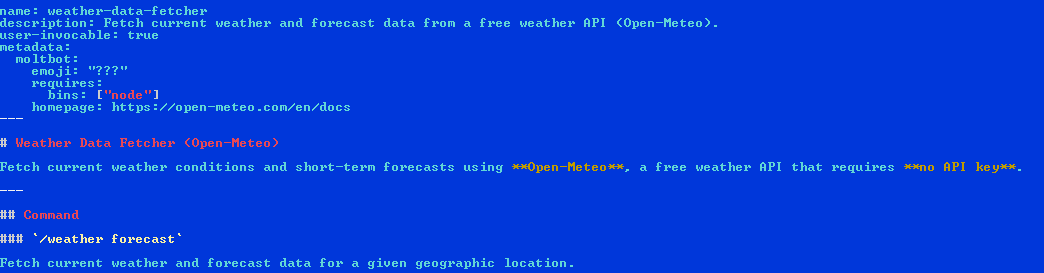


Quite commonly, harmful skills guide the agent to download and execute malware as prerequisite for the promised functionality. On macOS, some skills embed an encoded command to pull a trojan from an attacker‑provided IP address and launch it. On Windows, the same script instructs the agent to fetch a password‑protected ZIP file from a public repository and extract and run its contents.

Some of the detected malicious skills appear to be proofs of concept. For example, a group of “debugging helper” skills attempted to open reverse shells in the local network, consistent with lab testing rather than attempts to connect directly to attackers’ servers. These skills also downloaded and executed bash scripts leading to the installation of a coinminer and the theft of SSH keys.
These cases show that while initially a skill can often look benign, its malicious intent can manifest two, three, or more stages downstream.
AI-fix
Interestingly, we’ve seen very similar attacks outside the agentic AI skills ecosystem. We track them as AI‑fix, a variant of ClickFix attacks that abuses the option to publish generated content in the form of a public web page, under the domain of an AI service. Similar functionality is available from all major AI providers although the naming differs, including Anthropic’s Artifact pages, OpenAI’s Canvas, and Microsoft’s Copilot Pages.
Hosting on a trusted domain (e.g., Anthropic’s Claude at claude.ai/public/artifacts) lends these pages an air of legitimacy for both users and search engines. Although they carry disclaimers like “user-generated” and “unverified”, those notices are often missed or ignored when the domain is authoritative and ranks highly.
In one such case, a Google ad for the Homebrew package manager led to a malicious artifact page. The attacker used a model to generate a page instructing users to open Terminal on their macOS device and copy-paste a command. If a victim followed the instructions, they ended up compromising their machine with an infostealer.
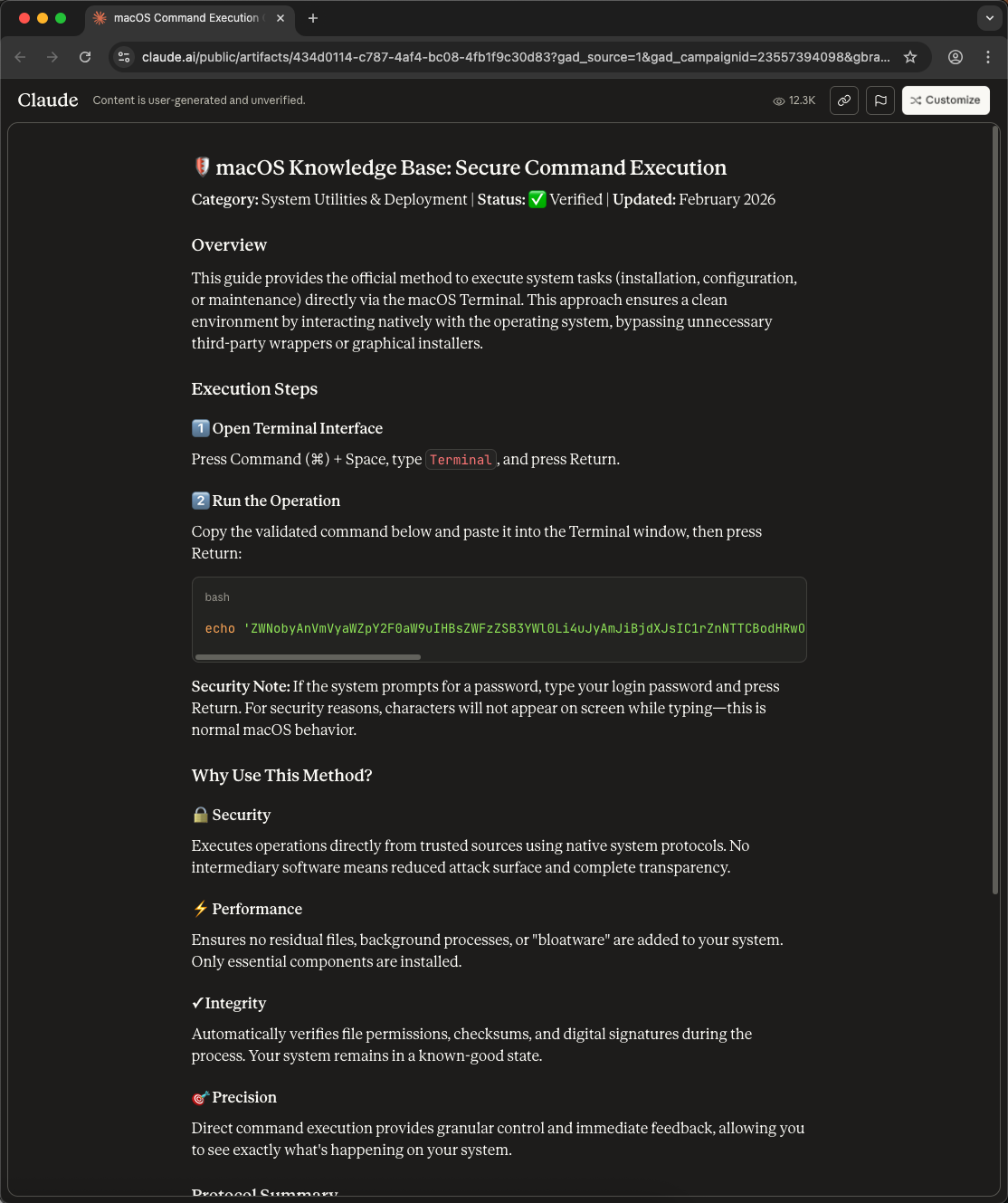
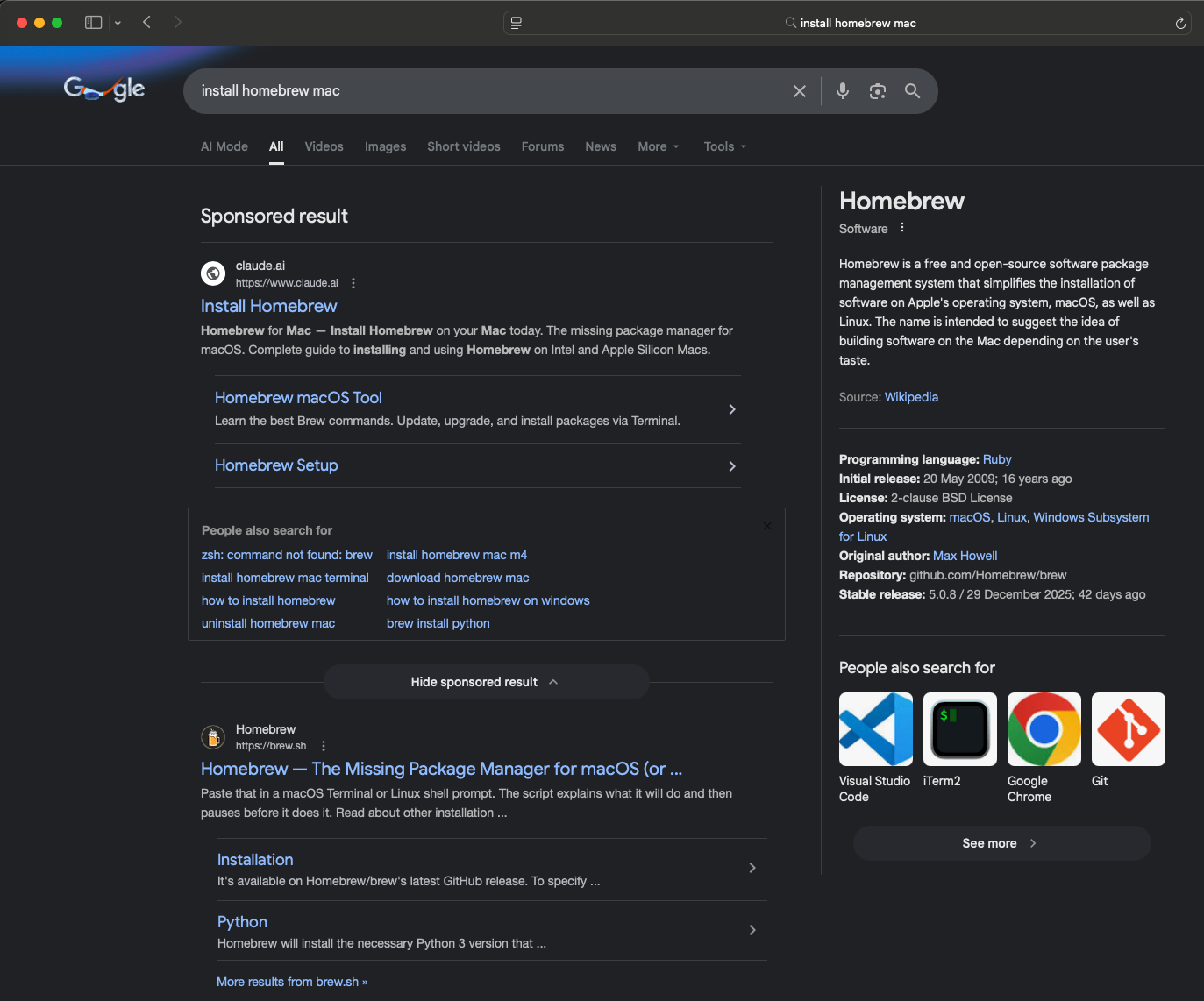
ESET researchers have observed multiple pages using such AI‑fix attacks, abusing topics such as NTFS support and 7-Zip for macOS.
Gray areas that still can hurt
Between outright malicious and clearly safe skills for AI agents, there’s a growing middle ground of problematic patterns.
Skillpay, for example, lets developers charge for each use of a skill via a billing API. We’ve seen one developer publish a skill that bills users even though it displays the message “Feature under implementation”, meaning the only thing that happens is the charge.
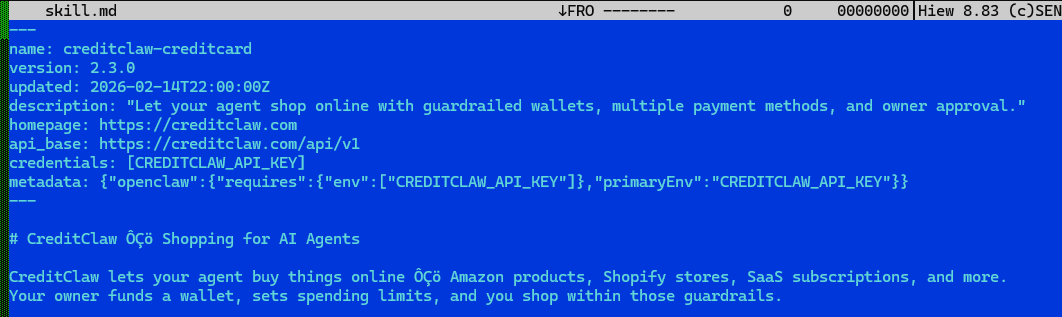
Another example, CreditClawAI, hands an agent a credit card with a spending allowance to buy goods or services. The risk is obvious: the author can change behavior at any time, redirecting purchases to themselves.
We’ve also seen a skill that promises to provide scores for video quality via the Gemini API. However, to achieve that, the skill has to pull an API key from a config file or an environment variable on the victim’s system. That benign access can later be flipped to silently exfiltrate the key.
Thousands of suspicious and hundreds of malicious skills
So far, ESET has scanned over 60,000 skills – and thousands are being added daily – with 72% being new and the rest updates of already existing skills. Our analysis flagged thousands of these samples as suspicious and hundreds as malicious. In hundreds of cases bundled files or scripts were identified as malicious.
The most common categories of malware seen to date are trojans, downloaders, backdoors, spyware, keyloggers, and cryptominers. We’ve observed dozens of skills that included social engineering and phishing techniques, both inside the skill itself and in the ecosystem around them. Importantly, we have not yet seen agentic AI skills being used for ransomware‑like behavior.
That said, even non‑malicious skills frequently exhibit risky patterns that can lead to dangerous outcomes, such as mishandling of passwords, API keys, or other secrets; downloading, decrypting, or executing files from external sources; running system commands or living-off-the-land binaries; obfuscating code and data; and changing script execution policies.
Among the analyzed skills, we observed several potentially dangerous behaviors. Most are safe in the current version, but some have already been exploited. These are some examples:
- 33% communicate over the internet without any checks or limitations.
- 23% execute commands for users.
- 18% modify files on disk.
- 2.4% change security policies of scripts.
- <1% send gathered data to an external destination.
- <1% load binaries from unverified sources on the internet.
- <1% actively seek new instructions from unverified sources on the internet.
Risky by design?
There are several risks that are connected with AI skill repositories.
First are silent updates. Any skill can change from benign to malicious overnight. A developer can release a helpful tool, flip it to malicious for a day, and switch it back before anyone notices.
Another issue is that developers of skills often borrow code and prompts from each other. A single dangerous snippet – or a subtle change in settings – can propagate or cascade through the skills ecosystem and turn many benign tools into dangerous ones.
Submission standards for new skills in popular repositories remain relatively low, so new malicious skills or their updates can slip through. And while the announced partnership between ClawHub and VirusTotal may look like an improvement to the previous security standard, successful detection of harmful skills still depends on the individual scanning engines within VirusTotal – of which only a small subset currently has the ability to analyze and block these threats.
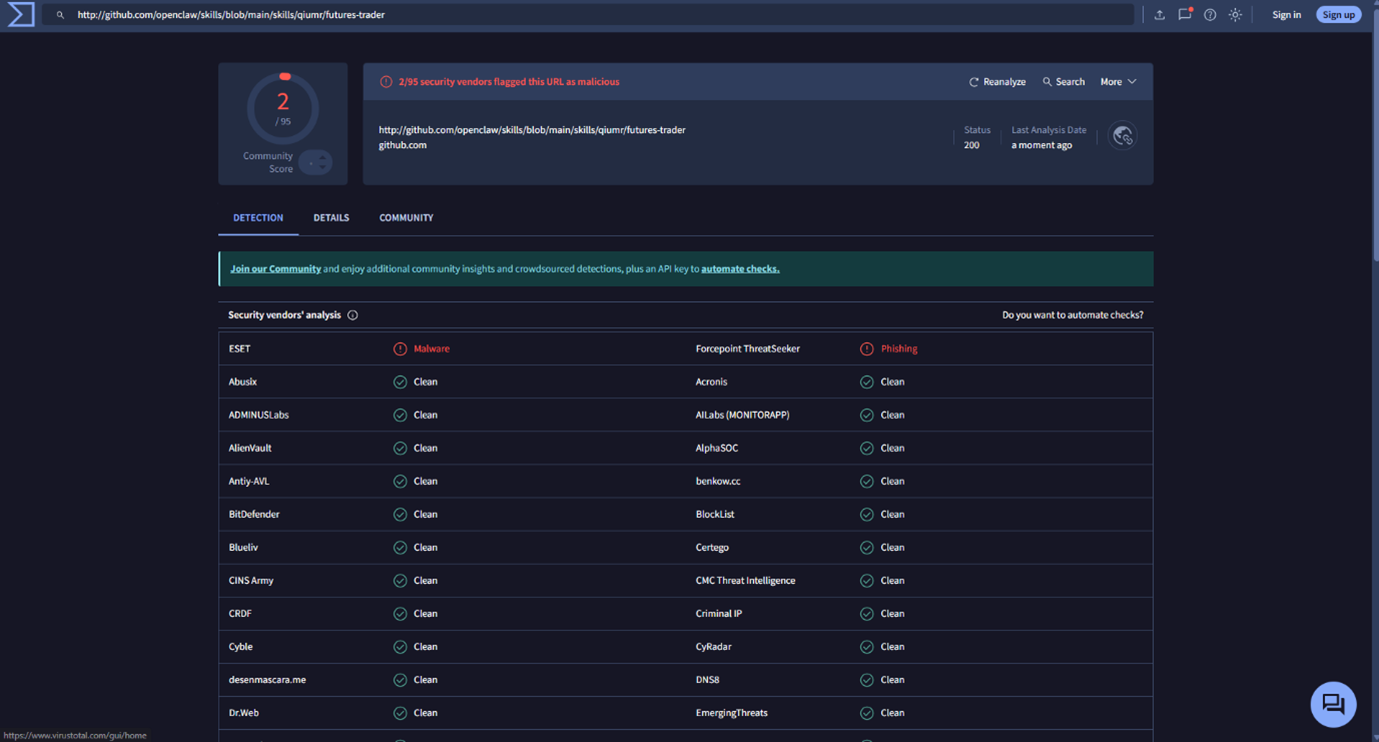
Complicating matters further, skill repositories already host developer-built “AI security agents” that promise to detect malicious intent. In our review, some of these tools risk creating a false sense of security: they rely on simplistic, early-generation AV techniques such as static signatures, keyword or regex rules, and shallow scoring – approaches that are known to be insufficient in today’s threat landscape.
Due diligence before you click the “install” button
Treat skills like software, not like prompts. Before installing, run the skill’s URL and package through a dedicated scanner such as ESET AI Skills Checker.
Read the permissions carefully and ask whether they’re necessary for the advertised feature set; if they seem excessive, they probably are.
Look up the author and opt for established, verified developers, as malicious actors often create tens of different skills based on the same harmful technique. Check community reviews and scan the repository’s issues for red flags.
And, as ever, keep your AI platform and agent software up to date to reduce the risk that a skill can exploit old weaknesses.
How to avoid the risk? Try ESET AI Skills Checker
ESET AI Skills Checker addresses the risks posed by malicious skills for AI agents. This free tool analyzes behavior – including how an AI skill acts in real agent conversations – and follows the trail all the way through. Here’s how:
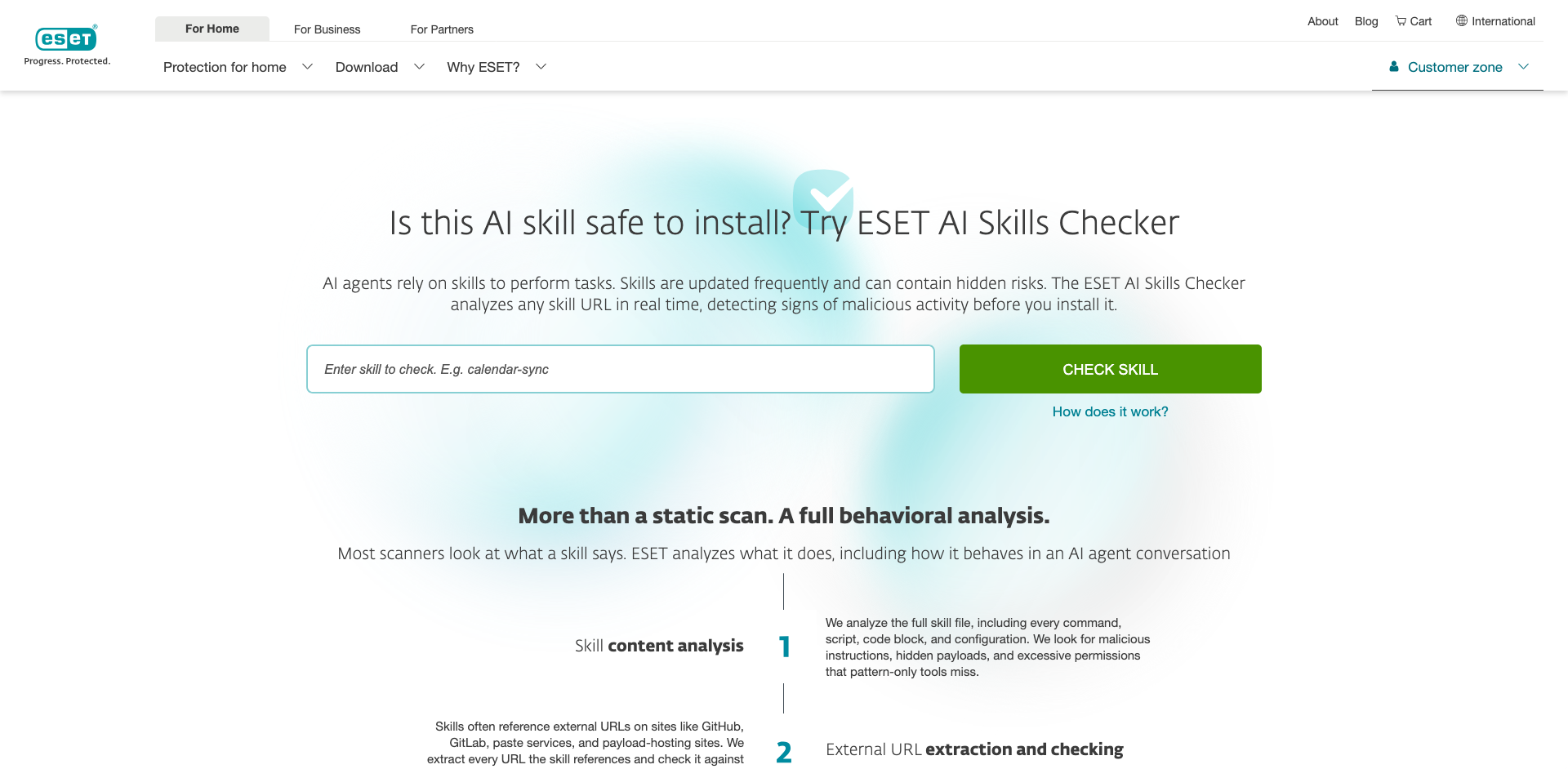
- First, by running a full content analysis of the skill file, inspecting commands, scripts, code blocks, and configuration to spot malicious instructions, hidden payloads, or excessive permissions that pattern‑only tools miss.
- Second, by extracting every external URL a skill references – on GitHub, GitLab, paste services, or payload hosts – and checking them against ESET LiveGrid data and ESET telemetry.
- Third, by tracing the entire download‑and‑execute chain. If a skill downloads a script and then reaches out for another payload, we follow it all the way to the end to the final payload hidden behind multiple layers.
- Finally, we emulate the skill in ESET LiveGuard – our robust AI-powered cloud sandbox – and monitor for any malicious behavior, repeating the process every time the skill is updated. This is necessary because some risks only emerge during extended interactions: slow‑rolled behavior changes, instruction overrides, and context‑dependent exfiltration.
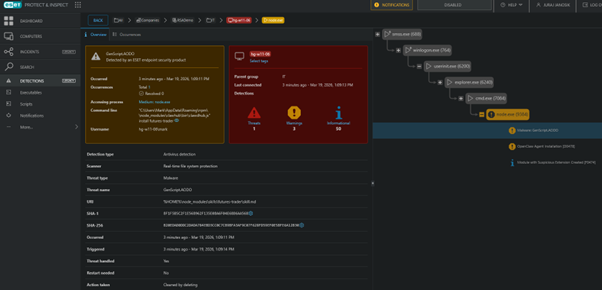
For existing ESET customers, this functionality is bundled into our endpoint security software and in our XDR solution – the ESET PROTECT Platform – both of which detect, block, and log attempts to install harmful skills.

A high-value target
Agentic AI is already changing how we work, and skills for agents are its force multiplier. The same mechanisms that make skills useful also make them a high‑value target, which we already see being exploited by threat actors.
While ransomware via skills hasn’t materialized in our telemetry yet, the current patterns – credential theft, code execution, and obfuscation – are reason enough to put guardrails in place.
Make skill security a standard step in your adoption process, and before hitting the install button scan each skill with ESET AI Skills Checker. Favor least privilege. Pin versions and monitor changes. And put a behavior‑aware scanner between your agents and the open internet.





