
Umělé inteligence a strojové učení jsou velkým buzzwordem posledních let. O jejich využití v kyberbezpečnosti mluvil Juraj Jánošík, expert na automatizovanou detekci, na konferenci SUSE Expert Days.
Umělá inteligence a strojové učení postupně proniká do různých oblastí lidské činnosti. Na plné rozvinutí potenciálu těchto technologií ovšem teprve čekáme. Strojové učení se bude čím dál častěji podílet na odhalování podvodů, posuzování a optimalizaci procesů, bude zlepšovat testování a vývoj nových řešení.
Podle našich dat už 82 % firem v Německu, Británii a USA dokonce využívá strojové učení k ochraně proti kybernetickým hrozbám.
Jako jakákoli jiná technologie má i strojové učení svá negativa. Existuje řada cest, jak jej mohou útočníci zneužít: ať už je to posílení malwaru, cílení na specifické oběti, vytěžování cenných dat nebo třeba ochrana botnetů před odhalením.
Softwarová řešení založená na umělé inteligenci se samy o sobě mohou stát atraktivním cílem. Útočníci se mohou například pokusit manipulovat s daty vytvářením nepřesných datasetů, případně tak ovlivnit správu.
Strojové učení lze zneužít i k obraně malware
Už nyní zkoušejí útočníci realizovat některé z uvedených scénářů. Dobrým příkladem jsou spammeři, kteří používají legitimní překladatelské služby založené na strojovém učení. Mohou tak posílat zprávy v širokém spektru jazyků. S větším množstvím adresátů roste i pravděpodobnost úspěchu podvodu.
Dalším příkladem může být malwarová kampaň Emotet, která podle všeho využívala tyto technologie k vylepšení cílení. Ačkoli dokázala nakazit tisíce obětí denně, dařilo se jí velmi dlouho a úspěšně vyhýbat detektorům botnetů a honeypotům. Emotet sbíral telemetrii potenciálních obětí a posílal je útočníkům na C&C server k analýze.
Podobné obranné mechanismy, které dokázaly dokonce odlišit operátory a programy výzkumníků, jsou velmi komplexní a drahé. Útočníci museli investovat obrovské množství energie a prostředků.
Umělou inteligenci mohou zmást i falešná data
Dalším rizikem, které budou muset experti řešit, a to zejména v oblasti kybernetické bezpečnosti, je manipulace strojového učení. K tomu stačí, aby útočník dodal programu podvržené vstupy. Stroj pravdivost dat zpravidla nemá jak ověřit. Tomuto druhu manipulace se říká Adversarial machine learning, do češtiny bychom mohli termín volně přeložit jako matoucí strojové učení.
Méně pokročilé skenery založené na umělé inteligenci mohou útočníci podvést a přimět je „rozhodnout“ se špatně, což v důsledku může vést ke snížení bezpečnosti vyhlédnuté firmy.
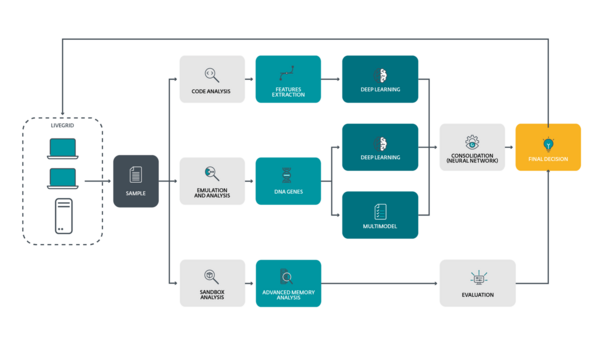
Je potřeba mít na paměti, že strojové učení není samospásné, a je dobré je doplnit alespoň prozatím dalšími technologiemi. ESET například umělou inteligenci využívá jako součást širšího spektra detekčních programů (jako jsou DNA detekce nebo UEFI scanner). Proti kyberhrozbám budoucnosti pomůže pouze vícevrstvá ochrana sítí.

Umělá inteligence a strojové učení postupně proniká do různých oblastí lidské činnosti. Na plné rozvinutí potenciálu těchto technologií ovšem teprve čekáme. Strojové učení se bude čím dál častěji podílet na odhalování podvodů, posuzování a optimalizaci procesů, bude zlepšovat testování a vývoj nových řešení. Podle našich dat už 82 % firem v Německu, Británii a USA dokonce využívá strojové učení k ochraně proti kybernetickým hrozbám.
Zajímáte se o další omezení umělé inteligence? Přečtete si celou studii „Machine-learning era in cybersecurity: A step towards a safer wolds ort he brink of chaos?“.