
S Jurajom Jánošíkom, odborníkom na umelú inteligenciu v spoločnosti ESET, sme sa v predchádzajúcich rozhovoroch rozprávali o umelej inteligencii ako aj o jej úlohe v oblasti kybernetickej bezpečnosti. V treťom rozhovore sme sa zamerali na jej konkrétnu aplikáciu v produktoch ESET.
V rozhovore sa dozviete:
- Čo je to DNA detekcia?
- Aké sú gény v škodlivom kóde?
- Ako vyzerá rozhodovací proces v produktoch ESET?
- Koľko modelov strojového učenia sa nachádza v detekčnom jadre ESET?
- Ako sa pozoruje správanie škodlivého kódu?
V našich rozhovoroch sme sa rozprávali o umelej inteligencii všeobecne, aj o jej použití v kybernetickej bezpečnosti. Skúsme si teraz vysvetliť, ako konkrétne funguje umelá inteligencia v produktoch ESET. Náš program skenuje nejaký súbor, čo sa deje na pozadí?
Keď skenujeme súbor, prejde cez niekoľko vrstiev analýzy, ktorá nám získa dáta. V princípe sa na neho pozeráme dvomi spôsobmi: staticky a dynamicky. Pri statickej aj dynamickej analýze sledujeme množstvo vlastností a získavame rôzne dáta, ktoré naše algoritmy obodujú. Vo finálnej fáze sa všetky tieto vstupy vyhodnotia a náš produkt rozhodne, či ide o škodlivý kód alebo nie. Proces čiastkového aj finálneho hodnotenia je komplikovaný a skladá sa z viacerých krokov, pričom do neho niekoľkokrát vstupuje aj strojové učenie.
V čom sa líši statická a dynamická analýza?
Pri statickej analýze algoritmus vyhodnocuje všetky dostupné informácie, ktoré vieme získať z kódu samotného. Napríklad aký je súbor veľký, aké sú tam sekcie, ako bol skompilovaný, v akom jazyku bol napísaný a podobne. Dokonca analyzujeme aj samotné inštrukcie, ktoré vykonáva procesor. Pri dynamickej analýze priamo v našom produkte spustíme tento kód v tzv. „emulátore“. To znamená, že kontrolovane vykonáme program bez toho, aby to mohlo zasiahnuť hostiteľský systém. Následne sa pozeráme, aké zmeny nastali, čiastočne nám to dá aj informáciu o správaní. Výstup z tohto procesu pretransformujeme do formy použiteľnej pre ďalšie vyhodnotenie. Je to také pomyselné laboratórium.
To neznie komplikovane.
V skutočnosti sa toho deje oveľa viac. My sa v podstate na kód pozeráme z rôznych uhlov pohľadu a vždy sa inou cestou snažíme získať čo najviac vstupných dát, ktoré následne vyhodnocujeme. Napríklad statická analýza sa v skutočnosti delí ešte na ďalšie časti. Je tam rozloženie kódu, extrakcia vlastností a vektorizácia, emulácia, DNA detekcia a podobne. Všetky informácie, ktoré získavame, prechádzajú rôznymi modelmi strojového učenia: neurónovými sieťami, klasifikačnými modelmi, LSTM algoritmami. Až na konci dlhého reťazca krokov dostaneme konkrétny výsledok.
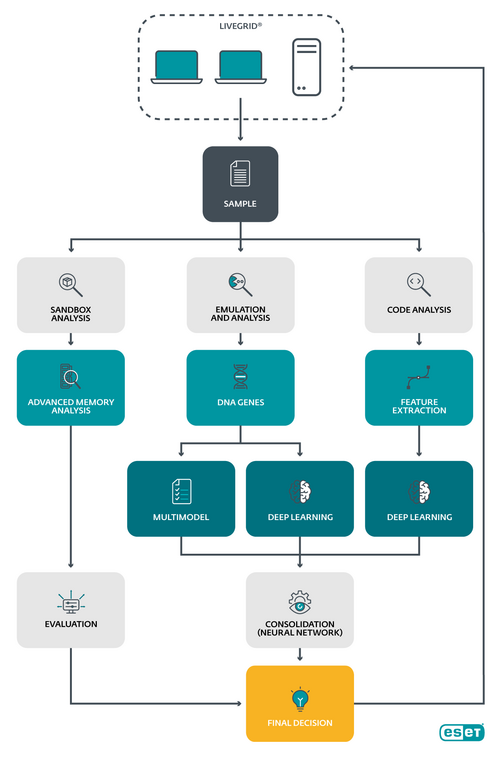
Vieš tieto procesy popísať konkrétnejšie ale tak, aby tomu porozumel aj bežný človek?
Skúsim priblížiť aspoň jednu zaujímavú časť statickej analýzy. Keď zachytíme podozrivý súbor, rozoberieme ho do najmenších detailov, až na úroveň niečoho, čo u nás voláme DNA. Ide o technológiu, k vytvoreniu ktorej nás inšpirovala príroda. V tejto DNA je skrytých mnoho vlastností analyzovaného súboru, ktoré nazývame gény. Práve tieto informácie potom zoberieme a nakŕmime nimi rôzne algoritmy strojového učenia, ktoré z nich dokážu odhadnúť, na koľko percent ide o škodlivý kód. Tých algoritmov máme viacero a tak musíme zobrať výsledky od každej jednej a tie potom vložíme do ďalšieho algoritmu (konkrétne do neurónovej siete), ktorá všetky tieto vstupy vyhodnotí a rozhodne, či naozaj ide o škodlivý kód alebo nie.
Znamená to, že škodlivý kód má určité špecifické gény?
Neexistuje niečo ako univerzálne zlé gény. My sa snažíme získať čo najviac vlastností kódu a ak sa objaví ich konkrétna kombinácia môže to predznamenávať niečo zlé. My vlastne pri analýze rozbijeme súbor na gény, a následne ich vložíme do našich modelov. Tu konkrétne hovoríme o tzv. „good old-fashioned AI“ prístupe, v rámci ktorého nášmu modelu priamo povieme, že ak sa vyskytne konkrétna kombinácia génov, pôjde pravdepodobne o škodlivý kód. Je to samozrejme zložitejšie, pretože môžeme detegovať napríklad len 4 zo 7 takýchto génov, no už aj to môže naznačovať, že ide o škodlivú vec.
Vieme pomenovať aspoň jeden takýto gén, ktorý sa obyčajne nachádza v škodlivých kombináciách?
Nie, pretože konkrétny gén sám o sebe nie je škodlivý a mimo určitých kombinácií môže byť úplne v poriadku. Práve špecifická kombinácia génov robí zo súboru potenciálne škodlivú vec.
Rozprávali sme sa o statickej analýze. Vieš nám priblížiť aj dynamickú analýzu?
Ako som spomínal, dynamická analýza prebieha v emulátore, čo je kontrolované prostredie, v ktorom môžeme bez problémov spustiť kód. Jedno takéto laboratórium sa nachádza priamo v našich produktoch a v reálnom čase na zariadení používateľa vyhodnocuje, ako by sa súbor správal. Podozrivé súbory si však posielame technológiou LiveGrid aj k nám do cloudu, kde si toho môžeme dovoliť oveľa viac. V cloude máme škálovateľný systém stoviek virtuálnych kontrolovaných prostredí, kde spúšťame podozrivé súbory a monitorujeme všetky ich aktivity. Výsledok takejto analýzy používame ako vstup pre rôzne vyhodnocovacie algoritmy. Bežne sa takéto prostredie označuje aj ako sandbox, naše riešenie je však ešte o stupeň komplexnejšie, preto nerád používam tento pojem pre našu technológiu.
Ako si mám predstaviť podozrivé správanie súboru?
Zoberme si napríklad wordovský dokument, ktorý obsahuje visual basic skript, ten spustí powershellový skript a ten sa následne snaží z neznámej url adresy, ktorá ani nepatrí Microsoftu, stiahnuť binárny spustiteľný súbor a spustiť ho. To je extrémne podozrivá aktivita.
Dá sa to preložiť do ľudskej reči?
Dokument vo Worde sa snaží z externej adresy stiahnuť kus pravdepodobne škodlivého kódu a spustiť ho. Používateľ o tom ani nevie, on vidí len obsah Wordu. Nutne to nevyžaduje ani žiadnu aktivitu používateľa, často stačí len otvoriť takýto súbor.
Dočítal som sa, že niekedy v sandboxe súbor nevyvíja aktivitu, akoby vyčkával. Aké metódy používajú výskumníci na to, aby tieto súbory takpovediac oživili?
V prvom rade sa už pred spustením snažíme zabezpečiť čo najvhodnejšie podmienky pre škodlivý kód. Ak napr. ide o wordovský súbor, tak ho spustíme vo Worde. Keď bol napísaný v roku 2013, tak použijeme vtedajšiu verziu programu. Ak ide o 64-bitový súbor, tak ho spustíme na 64-bitovom Windowse a podobne. Ak sa stane, že súbor spustíme a nič nerobí, no snaží sa napríklad inicializovať sieťovú komunikáciu, spustíme ho v inom prostredí – teda sandboxe, ktorý dokáže simulovať komunikáciu – a snažíme sa zmonitorovať jeho sieťovú aktivitu. Vtedy môže už aj niečo urobiť. Pred tým sa nedostal von a nevedel sa tak opýtať serveru útočníka, aké má plniť úlohy.
Poďme späť k analýze. Popísal si statickú a dynamickú analýzu. V nejakom momente sa predpokladám informácie z oboch spoja.
Z podozrivého súboru sa vždy pokúšame rôznymi technikami získať čo najviac dát. Tieto dáta vstúpia do rôznych modelov strojového učenia, z ktorých dostaneme niekoľko pravdepodobnostných hodnôt označujúcich, či ide o škodlivý kód alebo nie. Následne tieto pravdepodobnostné hodnoty vstupujú do konsolidačnej neurónovej siete, ktorá nám dá jednu, výslednú pravdepodobnostnú hodnotu. Napríklad, tento súbor je na 95% škodlivý. Toto je statická analýza.
Simultánne, ale zároveň nezávisle, prebieha pozorovanie súboru v emulátore, čo je dynamická analýza. V poslednom kroku sa výsledky statickej a dynamickej analýzy spoja, aby sa finálne vyhodnotili v poslednej neurónovej sieti. Tá nám dá finálny výsledok. Tento proces prebieha v našom cloude, aby sme nezaťažovali zariadenie používateľa a zároveň mali k dispozícií všetky možnosti našich technológií.
Koľko modelov strojového učenia je v celom rozhodovacom procese?
Od prijatia súboru až po finálne vyhodnotenie sa nachádzajú desiatky rôznych modelov strojového učenia, pričom sa celková evaluácia udeje približne do dvoch minút.
To znamená, že ak náš produkt deteguje podozrivú vec, ktorú nikdy pred tým nevidel, za 2 minúty rozhodne, či je to škodlivý kód alebo nie?
Našou prioritou je v prvom rade zastaviť potenciálne škodlivý kód a až potom zisťovať, čo to vlastne je. Samozrejme, aby sme používateľa neobmedzovali, nemôžeme zakázať všetko. Snažíme sa preto reakčný čas skrátiť čo najbližšie k nule. V našej poslednej aktualizácií sme vybrali modely strojového učenia menej náročné na výpočtový výkon a tieto prebiehajú priamo na zariadení používateľa. Rozhodujú sa autonómne a nemusia nikam nič posielať. Nemusia teda ísť cez náš cloud, čím sme výrazne znížili reakčný čas. Dá sa preto povedať, že umelá inteligencia, alebo niektoré jej prvky, má každý náš zákazník vo svojom zariadení.
Neznižuje to výkon zariadení používateľov?
Pri strojovom učení je problematické najmä trénovanie modelu. To je výpočtovo veľmi náročné. Samozrejme, aj samotný model vie byť výpočtovo náročný, ale aby bol použiteľný, väčšinou sa ho vývojári snažia prispôsobiť, aby hardvér používateľa zaťažoval čo najmenej. Samotná klasifikácia, teda použitie modelu, je v porovnaní s trénovaním zanedbateľné.
Spomínal si, že sa pri DNA detekcii používa „good old-fashioned AI“ prístup, stále je teda potrebný aj zásah človeka. Je to spôsobené našimi možnosťami, alebo to tak môže zostať navždy?
Ak by sa nám naozaj podarilo vytvoriť umelú inteligenciu na úrovni človeka, v podstate by mohla nahradiť ľudských pracovníkov. Aj v tomto prípade by sme ju však museli trénovať, pretože vonkajšie faktory a prostredie sa neustále menia. Ak by sme sa dostali až na úroveň super inteligencie, čo je otázne, tak sa nám ponúka viacero scenárov. Keďže bude AI múdrejšia ako človek, možno dokáže predpovedať aj budúce zmeny prostredia a odhalí zákony, na ktoré by ľudia nikdy neprišli. Ako sme sa ale rozprávali v predchádzajúcom rozhovore, je reálne, že ľudstvo nikdy nevytvorí super inteligenciu.
Juraj Jánošík
Na Slovenskej Technologickej Univerzite v Bratislave získal titul bakalára v aplikovanej informatike a titul inžinier v robotike. V roku 2008 nastúpil do spoločnosti ESET na pozíciu analytika škodlivého kódu. Od roku 2013 vedie tím zodpovedný za automatickú detekciu hrozieb a umelú inteligenciu, v súčasnosti je zodpovedný za integráciu strojového učenia do detekčného jadra. Pravidelne prednáša na odborných konferenciách po celom svete.